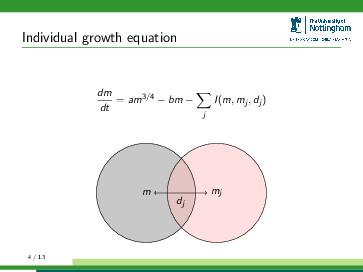
If you’ve made it this far in the series then you’ll have already explored software for writing, analysing data, preparing figures and creating presentations, many of which are designed explicitly with scientists in mind. You’re clearly interested in learning how to make your computer work better, which is great. If you’re willing to do this then why not take the natural next step and choose an operating system for your computer which is designed with the scientific user in mind?
Put simply, Windows is not the ideal operating system for scientific computing. It takes up an unnecessarily large amount of space on your hard drive, uses your computer’s resources inefficiently, and slows down everything else you’re trying to do*. Ever wondered why you have to keep updating your anti-virus software, and worry about attachments or executable files? It’s because Windows is so large and unwieldy that it’s full of back-doors, loopholes and other vulnerabilities. You are not safe using Windows.**
What should you do? Macs are superior (and pretty), but also expensive, and free software solutions are preferable. The alternative is to install a Linux operating system. If this sounds intimidating, but you own a smartphone, then you may not realise that Android is actually a Linux operating system. Many games consoles such as the PlayStation, along with TVs and other devices, also run on Linux. Do you own a Chromebook? Linux. You’ve probably been a Linux user for some time without realising it.
I have no idea why the Linux avatar is a penguin. It just is.
If you’re coming out of Windows then you can get an operating system that looks and behaves almost identically. Try the popular Linux Mint or Mageia, which both offer complete desktops with many of the programs listed in earlier posts pre-installed. Mint is based on the Ubuntu distribution, which is another common Linux version, but has a default desktop environment that will take a few days to get used to. The best thing about Ubuntu is that there is a vast support network, and whatever problem you come across, however basic, a quick web search will show you how to resolve it in seconds.
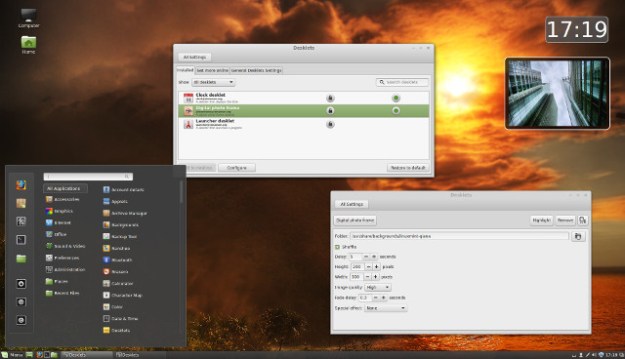
Your Linux Mint desktop could look like this sample image from their website. See, Linux isn’t so intimidating after all.
Unlike Windows, all these distributions are free to download, easy to install, and everything works straight out of the box. Within a week you will be able to do everything you could do on Windows. Within two weeks you will be realising some of the benefits. Like any change, it takes a little time to get used to, but the investment is worth it. There are literally thousands of operating systems, each tailored to a particular group of users or devices. Rather than getting confused by them all, try one of the major distributions first, which offer plenty of support for beginners. Once you know what you need you can seek out an operating system that is specifically tailored for you (or, if you’re really brave, create one).
Yeah, I know, DistroWatch.com may not look like the most exciting website in the world, but it does contain download links to every Linux OS you could imagine, and many more.
It’s possible to boot many of these distributions from a DVD or even a USB stick. This means you can try them out and see whether they suit before taking the plunge and installing them on your hard drive (remembering to back all your files up first, of course). If it doesn’t work out then take the DVD out of the computer and all will return to normal. An alternative, once you’ve set it up, is VirtualBox, which allows you to run a different distribution inside your existing operating system.
If you have an old computer which appears to have slowed down to a standstill thanks to all the Windows updates and is not capable of running the newer versions, don’t throw it away! This is exactly what manufacturers want you to do, and is why it’s not in their interests to have an efficient operating system. Making your computer obsolete is how they make more money. Try installing one of the smaller operating systems designed for low-powered computers like elementaryOS. You will get years more use out of your old hardware. A really basic OS like Puppy Linux will run even on the most ancient of computers, and if all you need to do are the basics then it might be good enough.
My preferred operating system is Arch, which has an accessible version Manjaro for moderately-experienced users. It’s not recommended for beginners though so try one of the above first. Why bother? Well, there’s an old adage among computer geeks that ‘if it isn’t broken, break it’. You learn a lot by having to build your OS from the ground up, making active decisions about how your computer is going to work, fixing mistakes as you go along. I won’t pretend that it saves time but there is a satisfaction to it***. Even if it means having to remember to update the kernel manually every now and again. One of its best features is the Arch User Repository, which contains a vast array of programs and tools, all a quick download away.

Behold the intimidating greyness that I favour on my laptop, mainly to minimise distractions, which is one of the advantages of the OpenBox window manager. Files and links on the desktop just stress me out.
As with every other article in this series, I’ve made it clear that you will need to spend a little time learning to use new tools in order to break out of your comfort zone. In this case there are great resources both online and from more traditional sources, such as the magazine Linux Format, which is written explicitly for the general Linux user in mind. You might outgrow it after a few years but it’s an excellent entry point. If you’re going to spend most of your working life in front of a computer then why not learn to use it properly?
With that, my series is complete. Have I missed something out? Made a catastrophic error? Please let me know in the comments!
* To be fair to Microsoft, Windows 10 is much better in this regard. That said, if you don’t already have it then you’ll need to pay for an upgrade, which is unnecessary when there are free equivalents.
** If you think I’m kidding, and you’re currently on a laptop with an integral camera, read this. Then go away, find something to cover the camera, and come back. You’re also never completely safe on other operating systems, but their baseline security is much better. For the absolutely paranoid (or if you really need privacy and security), try the TAILS OS.
*** Right up until something goes snap when you need it most. For this reason I also have a computer in the office that runs safe, stable Debian, which is valued by many computer users for its reliability. It will always work even when I’ve messed up my main workstation.